
整体架构#
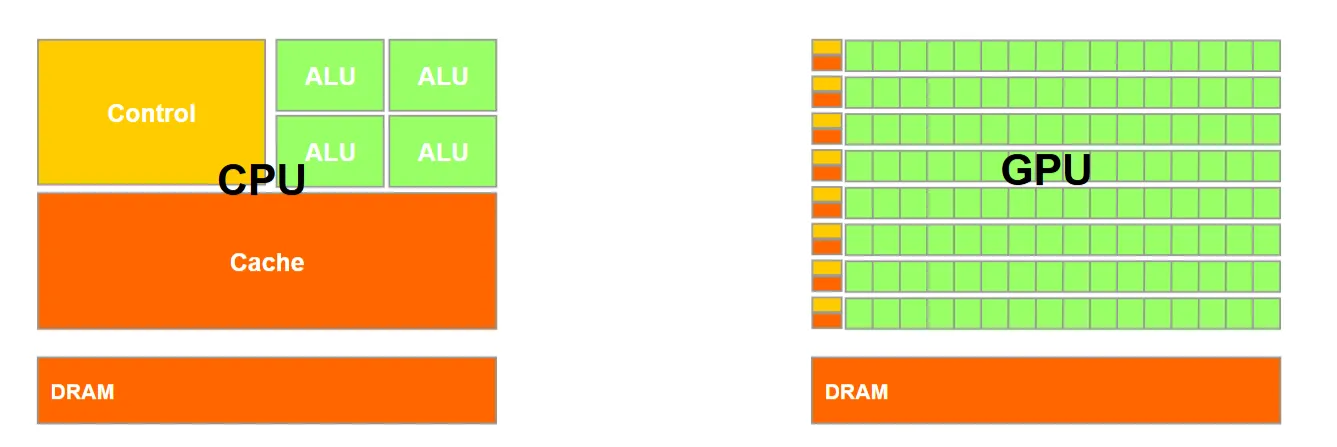
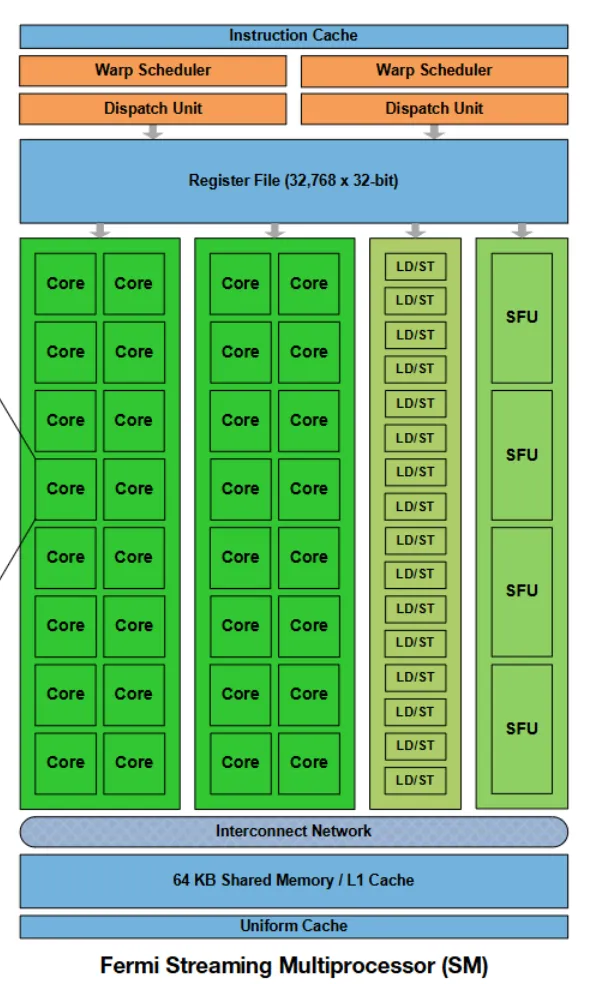
与CPU不同,GPU的控制逻辑较少,GPU的一行可以看作一个单元,这个单元叫做SM(Streaming Multiprocessor,流式多处理器)。 一个SM基本由以下几个单元构成
- CUDA Core:负责MAC计算,可以理解为GPU中的ALU
- SFU:负责进行特殊运算,如三角运算等
- LD/ST(Load/Store)单元:负责内存加载和存储
- Warp Scheduler:warp是线程的集合,通常是一组32个。在一个SM中,通常驻留了很多warp,Warp Scheduler复杂挑选出可以执行的Warp,交给Dispatch Unit
- Dispatch Unit:负责将一个Warp分给具体的单元(CUDA Cores、LD/ST 或 SFU)执行
自底向上#
一般来说,非CPU的加速计算资源,都有一套配套的运行环境。自底向上,分别是
硬件本身 --> Driver --> Runtime --> Libraries一般来说暴露给开发人员的都是Runtime和Libraries这两层
线程的分层与管理#
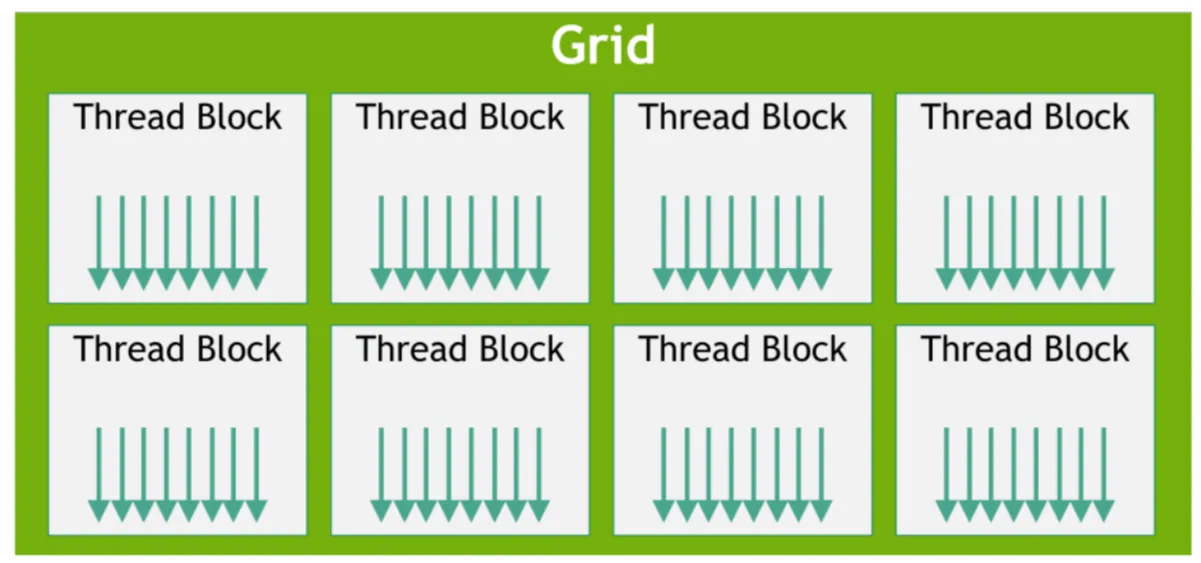
在GPU中,由于运用了超线程技术,需要对大量的线程进行管理,因此在启动一个kernel的时候,会对其中的thread进行分层
具体而言,多个threads组成一个线程块(Thread Block),然后多个线程块组成一个网格(Grid)
需要注意的是,在执行过程中,同一个Thread内的线程,都会在同一个SM上执行。
分好Thread Block后,会像之前说到的,一个Thread Block内的线程按照线程束(warp)分块,统一移到一个单元内执行,这时所有的线程执行的都是相同的指令 由于线程很多,调度器可以保证每个时刻,都有warp送到相应的资源中去计算或者访存,因此可以实现GPU的不空闲
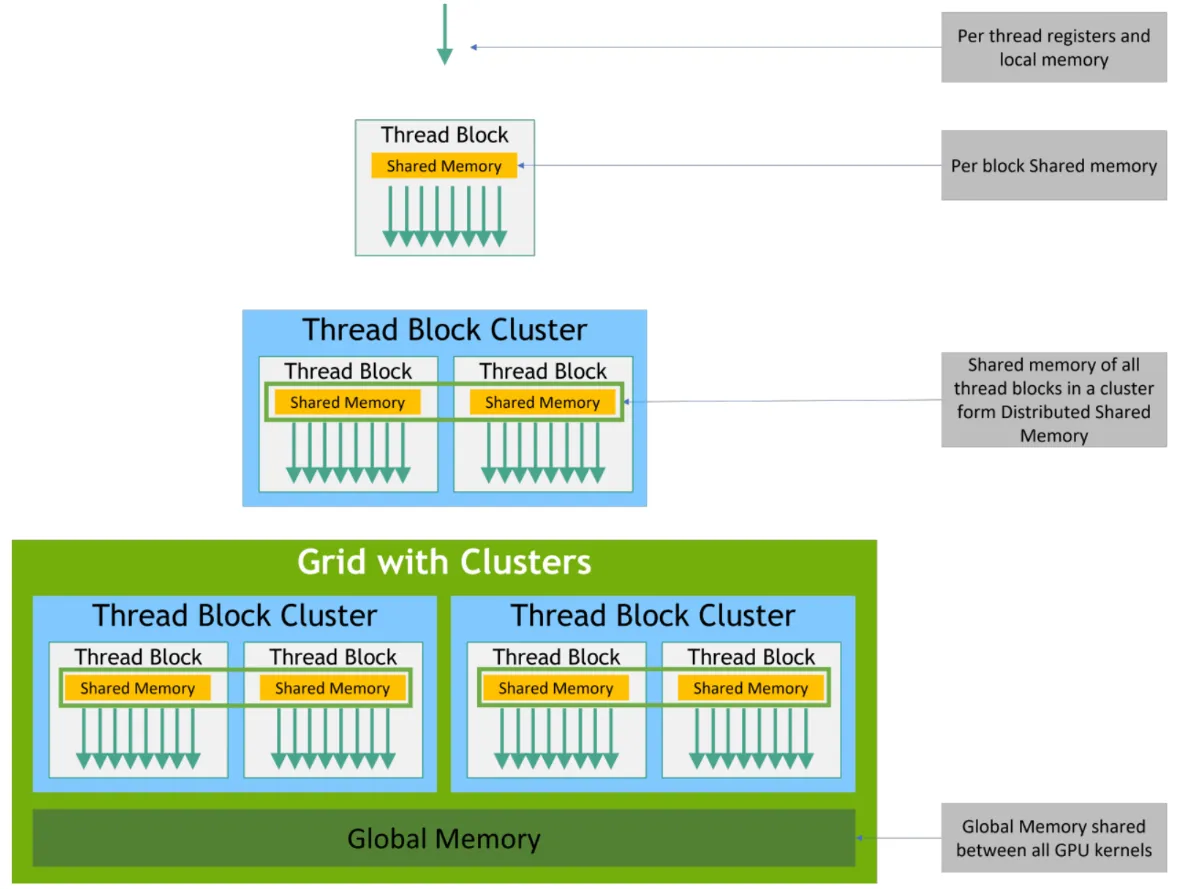
内存层级#
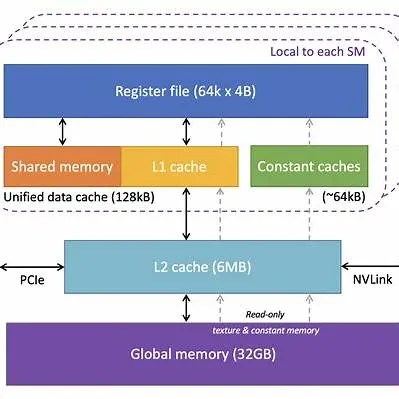
具体而言,可以主要分为三类
- Register File:由每个Thread拥有,线程结束后寄存器中的数据就会消失
- Shared Memory:由一个Thread Block所共享的资源
- Global Memory:片外,显卡的显存,整个Grid均可访问
由于主机(Host)和从机(Device)相互的内存空间不共享,因此需要在GPU中先申请内存空间,然后再把CPU中的数据拷贝过去。
cudaError_t cudaMalloc(void** devPtr, size_t count);其中devPtr在使用时,一般需要使用void**的强制类型转换转换为对应的输入
如
cudaMalloc((void **)&d_a, size);双指针需要取指针的地址,因此是&d_a
这里申请size_t个字节的全局显存
cudaError_t cudaFree(void* devPtr);这里释放显存
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind);这里完成数据的拷贝
cudaMemcpyKind kind一共有四种,分别是
cudaMemcpyHostToHost:主机 → 主机cudaMemcpyHostToDevice:主机 → 设备cudaMemcpyDeviceToDevice:设备 → 设备cudaMemcpyDeviceToHost:设备 → 主机
共享显存和全局显存的使用#
若没有明确分配共享显存的空间,默认使用的是全局显存
__shared__ int smem[256];可以使用该方式分配共享显存。需要注意的是,共享显存为一个SM处理器所占有,因此在运用时需要注意开的大小和Block内的线程数量需要进行对齐